

















Jmail and the Jeffrey Epstein files PDF: Why a webmail-style viewer is spreading now
A wave of interest is building around “jmail” and “Jeffrey Epstein files PDF” as newly released federal document tranches are reposted, remixed, and repackaged across the internet. The flashpoint is a simple usability problem: millions of pages of scanned records can be difficult to navigate in their original form, and a new third-party viewer is presenting a subset—especially email-style records—in a familiar inbox-like layout that feels searchable and immediate.
The result is a fast-moving mix of legitimate public records, political crossfire, and predictable scams trying to exploit the demand for “the full PDF.”
What “Jmail” is — and what it is not
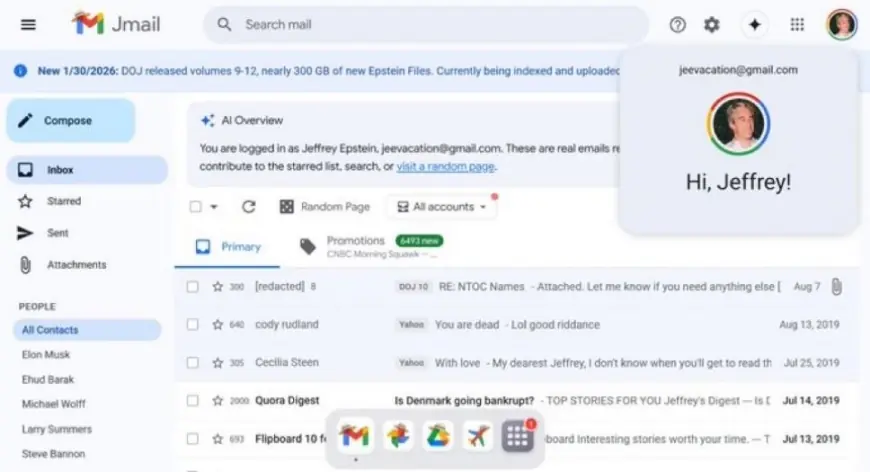
“Jmail” is being used as a nickname for an online viewer that organizes parts of the newly published Epstein-related records into an interface that resembles an everyday email inbox. Instead of forcing users to open hundreds of separate files and manually search them, the viewer indexes text and metadata so messages can be filtered, searched, and grouped.
What it is not: an official government portal, a new leak, or proof of access to private accounts. The viewer does not “log you in” to anything in a technical sense; it is a presentation layer over already-public material.
Because the interface is so familiar, it can create a misleading sense of authenticity or completeness. Users may feel like they are seeing an entire correspondence history when, in reality, they are viewing a curated or technically extracted slice of what has been published so far.
Why the official PDFs are hard to use
The current release is massive. The Department of Justice announced on Friday, Jan. 30, 2026, that it published roughly 3.5 million pages responsive to the Epstein Files Transparency Act, along with large volumes of images and videos, after the law took effect in late 2025.
Large public-record releases like this often come in bulky batches: scanned pages, inconsistent file naming, partial redactions, and uneven text quality. Even when documents contain searchable text, formatting glitches and scanning artifacts can break search accuracy, misread dates, or split numbers and names in ways that fuel confusion.
That’s the gap third-party tools are stepping into: they turn “a warehouse of PDFs” into something that feels like a database.
What to expect inside “Epstein files” PDFs
The phrase “Epstein files” has become a catch-all, but the published records can include very different kinds of material:
-
investigative paperwork and administrative records
-
correspondence, including email printouts and attachments
-
filings, exhibits, and other court-related documents
-
logs, contact lists, and travel-related records in varying forms
Inclusion in a document dump does not automatically imply wrongdoing by anyone named. Some records contain unverified claims, partial context, or references that require corroboration. And because many records were produced for legal or investigative purposes, they may include inconsistent identifiers, incomplete threads, or heavily redacted passages that are easy to misread.
Why details can look inconsistent or “wrong”
Two technical issues have repeatedly shown up in large document sets like this:
Flattening and encoding artifacts. When email content is exported into static documents, special characters and formatting markers can appear or distort text. That can make names, ages, and dates look contradictory across different copies of the same material.
Duplicate and near-duplicate documents. Big productions often contain repeats—either exact duplicates or slightly different versions of the same record with different redactions. That can lead users to believe something “changed” when they are simply viewing different processing passes.
The practical takeaway: if a claim hinges on a single screenshot or a single page pulled from a long PDF, it is worth checking whether a fuller thread, a second version, or a related exhibit exists.
The scam risk around “Jeffrey Epstein files PDF”
High-demand document releases reliably attract bad actors. Over the past week, multiple sites have circulated sensational titles promising explicit content, “full unredacted PDFs,” or “hidden videos,” sometimes bundled with aggressive download prompts.
Red flags are consistent: strange file names, pop-up download buttons, requests to install software, and claims that you must “verify” or “unlock” access. Some of these pages can be pure bait for malware, while others attempt to harvest email addresses or payment details.
Key takeaways
-
“Jmail” is a third-party viewer that makes public records easier to search, not a source of new leaks.
-
The official release is enormous, and scanning/formatting issues can distort text in ways that fuel misinformation.
-
Be cautious with “full PDF” claims that push downloads or sensational promises; stick to official repositories and primary documents.
What to watch next
The release is likely to remain a rolling story through February, for two reasons: the volume is still being processed and public scrutiny is intensifying. Congressional pressure is also building around access, redaction standards, and whether lawmakers and investigators can review more complete versions under controlled conditions.
At the same time, the most meaningful developments will be the ones tied to verifiable, date-stamped actions—new filings, formal statements, and clearly attributable records—rather than viral screenshots stripped of context. As the dataset grows, the signal-to-noise problem will get harder, not easier, making careful verification the central challenge of the next stage.
Sources consulted: U.S. Department of Justice, Associated Press, ABC News, Congress.gov