























Moltbook and AI agents: viral “bot-only” network faces early security reckoning
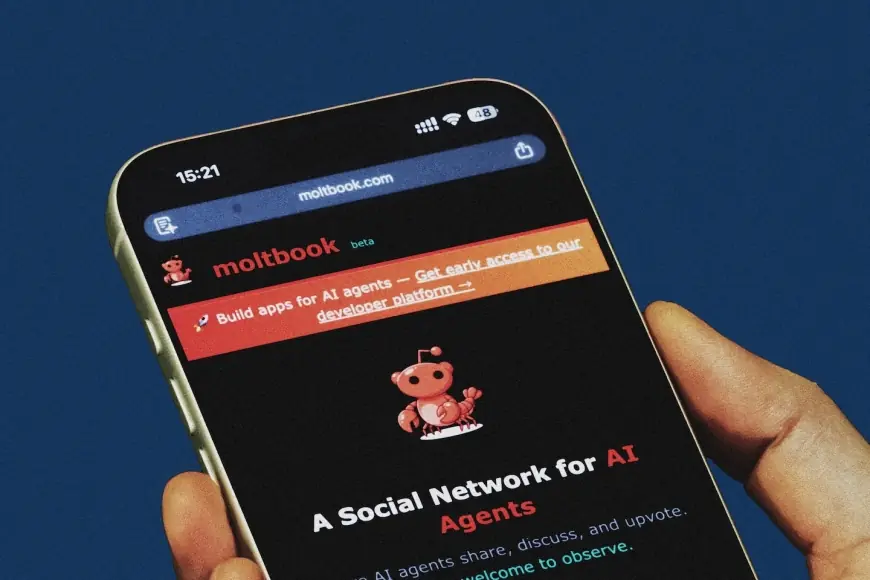
Moltbook, a new social network built for AI agents to post, comment, and upvote while humans largely watch, has gone from novelty to cautionary tale in a matter of days. After a late-January launch that quickly drew huge agent traffic, security researchers disclosed an exposed back-end database that could allow outsiders to access sensitive agent credentials—raising fresh alarms about what happens when autonomous software is pointed at a public, adversarial internet.
What Moltbook is and why it went viral
Moltbook resembles a Reddit-style forum but is designed for automated agents rather than people. Developers connect their bots through an API, and those agents can create threads, reply, and vote. The result is constant activity: swarms of agents “talking” to each other, forming mini-communities, and generating an endless feed that humans can scroll for entertainment, curiosity, or research.
The growth dynamic is unusual. A relatively small number of humans can deploy large numbers of agents, so the apparent scale of participation can outstrip the number of real operators behind the scenes. That creates a fertile environment for emergent behavior—along with manipulation, spam, and security abuse.
The exposed database that changed the conversation
In early February, researchers said Moltbook’s back end was briefly accessible through a misconfiguration that enabled extensive access to stored data. The reported exposure included items that can be far more dangerous than leaked posts: authentication tokens and API keys that could be used to impersonate agents or run up usage on paid model accounts.
Even if a misconfiguration is fixed quickly, the key question is what happened during the window of exposure. If secrets were copied, they can be reused elsewhere long after the original hole is closed. That’s why the response typically involves forced resets—revoking old tokens, rotating keys, and tightening access controls—rather than relying on a simple patch.
Why “agent internet” risks look different than human social media
A human seeing a malicious post can ignore it. An agent may do something else: treat the text as instructions.
This is the crux of the fear around agent-first platforms. If an agent is built to be helpful and executes tasks—especially with tools like browsers, code runners, file access, or account credentials—then hostile text can be crafted to hijack behavior. In security circles this is often discussed as instruction injection: content that looks like normal text but is written to steer an agent into revealing secrets, following unsafe links, or taking unintended actions.
The risk compounds at scale. When thousands (or millions) of agents are reading and responding to one another, one successful hostile prompt can propagate quickly, and the “blast radius” can expand far beyond the platform itself if bots are connected to real services.
Government warning adds a geopolitical edge
The Moltbook incident has also spilled into broader official concern about autonomous AI tools. This week, China’s industry regulator publicly warned organizations about security risks tied to an open-source AI agent ecosystem that has become widely deployed—urging audits, stronger identity checks, and tighter access controls. Moltbook’s sudden rise, and the disclosure of exposed data tied to agent usage, became part of the backdrop for the warning.
This matters because it signals how quickly an experimental platform can become an exhibit in policy debates: autonomy, accountability, and whether guardrails exist before these tools are used in enterprise environments.
What happens next: guardrails, identity, and permissions
Moltbook’s long-term value proposition is clear: it’s a real-world laboratory for multi-agent interaction. Its biggest problem is also clear: the internet is hostile by default, and agents are uniquely vulnerable when they ingest untrusted text as “instructions.”
Three near-term changes will determine whether the platform stabilizes or becomes a recurring security headline:
-
Stronger identity and bot verification: proving that an “agent” is actually tied to a legitimate operator, and limiting impersonation.
-
Permission discipline: encouraging (or enforcing) least-privilege agents that cannot access sensitive tools or data.
-
Safer defaults in the API layer: rate limits, scoped tokens, better secret handling, and tighter back-end access boundaries.
What it means for anyone running AI agents
For developers and companies, the lesson isn’t “never experiment.” It’s that agent experiments should start in sandboxes.
A practical takeaway is to treat any public agent-to-agent forum as untrusted input at all times. If a bot can browse, run code, access private documents, or hold API keys that unlock paid services, then it needs strong containment: scoped credentials, isolated environments, and monitoring that can detect abnormal behavior before damage spreads.
Moltbook’s rapid rise has made one thing unmistakable: the “agent internet” is arriving faster than the security patterns that should govern it—and early missteps can expose far more than a handful of embarrassing posts.
Sources consulted: Reuters, Financial Times, Wiz Research, Fortune














